Deep learning is a branch of machine learning, which is part of artificial intelligence. It involves training artificial neural networks with data to perform tasks such as image and speech recognition, natural language processing, and more. The “deep” refers to the multiple layers in these networks, which allow them to make complex decisions.
For example: In image recognition, the first layer identifies basic shapes, while subsequent layers identify more complex features and entire objects.
Deep learning has shown remarkable success in various fields and is driving significant technological advances. It’s a powerful tool for making sense of large, complex datasets and solving problems that were once thought to be beyond machines’ capabilities.
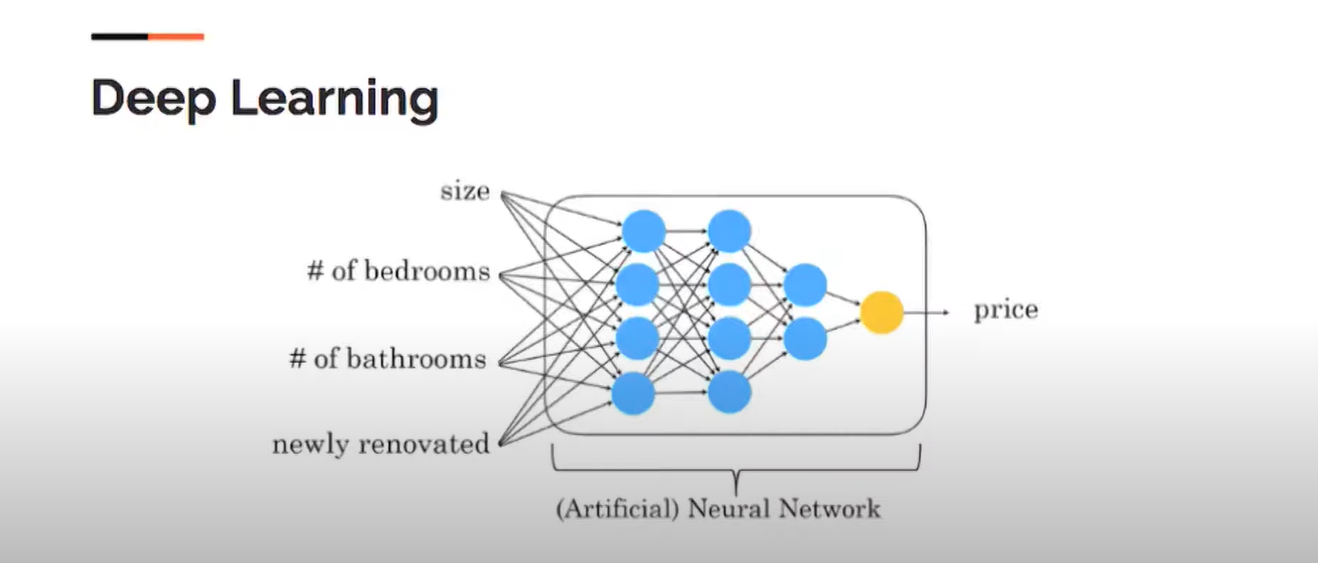
In the above diagram, we can see circles here are called nodes or neurons.
Vertically, circles are visible and are combined to form a networking layer, just like we have inside this network; three layers are blue, and one is orange. You see here where data coming is called the input layer, and where we have the last layer, there is a single neuron inside it, called the output layer. We have only the input layer and the output layer under our control.
In this example, we can see several features such as size, number of bedrooms, number of bathrooms, and whether the house was newly renovated, which determine the price. Additionally, deep learning is being used to analyze and retain the data.
Introduction to Neural Networks
Neural networks are fundamental in artificial intelligence (AI) and machine learning. They serve as the backbone of many AI applications today. Inspired by the human brain, neural networks are designed to recognize patterns, learn from data, and make intelligent decisions.
A neural network is a system of interconnected nodes, or “neurons,” that work together to process information. Each neuron receives input, processes it, and passes the output to the next neuron in the network. This process continues until the final result.
Perceptron
A Perceptron is the simplest type of neural network and acts as the building block for more complex networks. It consists of a single layer of neurons (also called nodes) that process input data to produce an output. Here’s how it works:
- Inputs: The perceptron receives multiple inputs, each representing a data feature.
- Weights: We multiply each input by a weight that determines the input’s importance.
- Summation: We sum the weighted inputs.
- Activation Function: The sum is passed through an activation function to produce the output.
Multi-layer Perceptrons
A Multi-layer Perceptron (MLP) is an extension of the perceptron with multiple layers of neurons. These layers include:
- Input Layer: Receives the raw data.
- Hidden Layers: Intermediate layers that process the data. An MLP can have one or more hidden layers.
- Output Layer: Produces the final result.
MLPs are powerful because they can learn complex patterns by adjusting the weights through backpropagation.
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are revolutionizing the field of computer vision and beyond. These powerful models mimic the human brain’s ability to recognize patterns, making them incredibly useful for tasks like image and video recognition, medical image analysis, and even autonomous driving. By automatically learning to detect features such as edges, textures, and shapes, CNNs can transform raw data into actionable insights with unparalleled accuracy.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are game-changers in sequential data analysis. Unlike traditional neural networks, RNNs have a unique ability to remember previous inputs, making them perfect for tasks like language modelling, speech recognition, and time series prediction. By capturing temporal dependencies, RNNs can understand context and sequence, enabling more accurate and meaningful predictions.